Changelog
New features, improvements, and fixes for Solair AI.
June 2026
Fast & Cool Modes
You can now choose how the app runs on your device, right at the top of Settings.
- Fast: full speed for the quickest replies
- Cool: paces generation to about half speed so your phone stays cooler during long chats
Switch anytime. Fast stays the default.
June 2026
Deep Research
Tap the globe to switch it on. Solair runs several searches, reads the sources, and writes one in-depth answer with citations. All on your device.
Better Web Search
Searches every time, remembers results for follow-up questions, and shows preview images and sources you can tap.
Smoother Model Switching
Swapping models no longer fails with false "out of memory" errors, and Auto Mode now sticks with the smarter model for the rest of the conversation instead of pausing to swap back.
Context Limit Setting
Cap how much conversation history the AI processes to keep long chats fast and memory use low (Settings > Advanced).
Beautiful PDF Export
Share any conversation with proper headings, lists, and tables.
Faster and Smoother
Quicker responses, smoother scrolling, lower memory use.
Stability
Lots of stability fixes and under-the-hood improvements.
May 2026
New Models
- Gemma 4 12B is now available
- Gemma 4 E2B QAT and E4B QAT added for lighter on-device use
Smarter Memory & Search
- News searches now actually search your topic (e.g. "spacex news" finds SpaceX stories, not generic headlines)
- Smarter memory: stops getting in the way of roleplay, creative prompts, web searches, news, and health questions
- New Memory depth setting to balance speed vs. recall when searching your docs and past chats
- Snappier replies with large chat history: memory no longer pauses the screen before answering
Under the Hood
More improvements under the hood. Should have called it 2.6!
May 2026
Memory & Knowledge, Your Second Brain, Finally Remembers
Solair now actually knows you. It quietly indexes your past conversations, your facts, and your documents, all on-device, so the next time you ask "what did we decide about that project?" or "what's my recipe again?", it just remembers. No re-explaining. No re-uploading. The longer you use it, the smarter it gets about you.
- New unified hub in Settings combines Facts, Past Conversations, and Documents in one place
- Search across past conversations: Solair can recall details from earlier chats (on by default, indexed overnight while charging)
- Source citations: AI answers now show which of your notes, documents, or past chats they drew on, tap to see the exact excerpt
- Onboarding refresh: clearer "Memory & Knowledge" card during setup so you can pick what to enable
- Privacy hardening: deleting a chat (or using the duress code) now also removes it from the index. Nothing lingers.
Photo Wallpapers
Set your own image as the chat background. The theme preview circle now shows the photo so you can see what you picked at a glance.
Progressive Blur Header
The chat view header now fades into a soft progressive blur as you scroll, keeping the focus on your conversation.
Chat Improvements
- Delete individual messages: long-press any message (yours or the AI's) then Delete
- Model & speed attribution (opt-in in Settings > Display): shows a tiny line under each AI reply like Gemma 3 4B · 42 tok/s, so you can see when Auto Mode switches between Fast/Smart/Vision
- Toggles persist: web search and thinking-mode switches now remember their state across app restarts
Sidebar & History
- Adaptive sidebar width: scales with your screen on iPhone, capped sensibly on iPad/Mac
- Richer history previews: more text per row so you can find chats at a glance
Improvements
- Smarter launch, Solair now restores the exact model you had loaded last (LLM or VLM), and prefers your downloaded MLX models over Apple Intelligence
- Auto-load fallback tries progressively smaller models when a load fails, instead of giving up
- Background Intelligence runs more reliably: throttled to avoid thermal slowdowns, with manual-run, rate-limit, and scheduling gaps closed
Bug Fixes
- Audio: opening Solair no longer pauses music or podcasts playing in other apps
- Tool calls on Gemma 4: fixed garbled news/health tool calls leaking into chat bubbles, truncated XML tags being rejected, and multi-call JSON tools sharing parameters
- Health insights: point-in-time metrics (like heart rate) are now averaged instead of summed; goal progress no longer shows NaN% if target is zero
- Custom RSS feeds: URLs are now validated before being added
- Voice mode: VAD audio buffers are now processed in order, fixing occasional choppy recognition
Performance & Stability
- Lower idle CPU
- Faster message rendering (parsed-content cache seeded on init)
- Token-generation garbage check now scans only the trailing window instead of full output
- Mac Catalyst fixes: builds and runs cleanly on Mac, and no longer cuts off responses at ~50 tokens due to a bogus low-memory warning
- Updated MLX to 0.31.4 for the latest inference improvements
- Background panel now opens fully expanded for easier reading
- Many more improvements under the hood
May 2026
New: Background Intelligence
Solair can now work for you while the app is closed, using Apple Intelligence on-device:
- Smarter sidebar: chats get AI-generated titles and one-line summaries automatically
- Morning brief: a daily notification combining your calendar, HealthKit data, and the thread of your last conversation
- Weekly health digest: charts and a personal wellness score every week
- Memory tidying: old saved memories are merged overnight, with a 7-day trash if you want to undo
- Opt-in, with a master toggle and per-feature switches in Settings. Pauses when your phone is hot or low on battery. A "Run now" panel lets you trigger any job on demand.
Better
- News now works in every language. Tapping the French (or any localized) news prompt now actually calls the news tool. Previously the keywords didn't match the translated text.
- Onboarding refresh: clearer hero copy, better iPad scaling.
Fixes
- Stop button is now instant when using Apple Intelligence (previously kept generating for several seconds after you tapped stop).
- "Load a model" button no longer appears when Apple Intelligence is your active model.
- LFM2-VL vision model now works correctly for both text and image messages (was silently falling back to Apple Intelligence).
- Memory injection no longer interferes with news/health tool calls. Saved memories were causing the model to hallucinate answers instead of fetching real data.
May 2026
New: Skills
Turn Solair into a focused assistant for any task. Skills are reusable presets, like "Code Reviewer," "Travel Planner," or "Email Polisher", that shape how Solair responds, all within your normal chat.
- Create your own, or let AI generate one from a quick description
- Import and export SKILL.md files to share with others
- Delete the ones you no longer use
Faster Gemma 4
Gemma 4 models now run up to 20% faster on Apple Silicon thanks to under-the-hood inference optimizations.
New: iPad Keyboard Shortcuts
Common actions like send, new chat, and voice mode now have hardware-keyboard shortcuts on iPad.
Polish & Fixes
- Cleaner input bar with a new paste button
- Fixed HTML responses getting cut off
- News categories now load correctly
- More under-the-hood improvements
May 2026
News Intelligence
Ask for the latest news and get AI-summarized headlines from top sources (Google News, AP, BBC, Reuters). Solair fetches live RSS feeds, summarizes them, and answers your follow-up questions, all on-device. Supports 14 languages and adapts to your app language. Manage your sources anytime in Settings.
Scroll-to-Bottom Button
When you scroll up in a conversation, a glass button now appears to jump back down to the latest message. Tapping it during a response also re-enables auto-scroll, so you can keep following along as the AI generates.
Storage Reclaimed Properly
Deleting a downloaded model now immediately frees up your disk space, no need to restart the app. We also added a "Delete All Downloaded Models" button in Settings to quickly recover storage in one tap.
Combined Memory & Context Gauge
The device memory and context window indicators are now unified into one gauge. The RAM pie chart sits at the center, with a ring around it showing how much of the context window you've used. Tap it to see the full breakdown, model weights, system memory, and tokens used (e.g. 2.4K / 32K), all in one popover.
Send Button Redesigned
The send button now renders as true liquid glass with its own independent glass context. As an option, you can also transform it into a procedural gold plasma ring with specular highlights and a soft glow. A small detail, but hey, it's ok to have fun.
Better Voice Mode for More Languages
Chinese, Japanese, Korean, Hindi, and German now automatically use Apple's best built-in voices instead of Kokoro, for much better pronunciation. The app picks the highest-quality voice available (Premium > Enhanced > Default), and Voice Mode starts instantly with no download needed. For even better quality, a tip in Voice Settings explains how to download Premium voices from iOS Settings.
Updated Model Catalog
- Added Gemma 4 E2B and E4B uncensored variants
- Added DeepSeek R1 0528 8B, the most popular MLX model right now
- Removed outdated models (Mistral 7B v0.3, SmolLM2 1.7B, Dolphin 3.0 8B) that are now outperformed at their size
Bug Fixes
- Fixed tok/s display staying low after web search or tool use, speed now updates live during follow-up responses instead of showing a stale number
- Fixed misleading "Not enough memory" errors, some model load failures (especially mxfp4 models) were incorrectly shown as memory errors. The app now shows the actual reason
- Fixed mxfp4/mxfp8 model loading, models with missing quantization config are now automatically patched
- Fixed Voice Mode showing "Kokoro TTS not ready" when using a language that doesn't need Kokoro
- Fixed the "Speak" button in chat trying to download Kokoro for languages handled by Apple TTS
May 2026
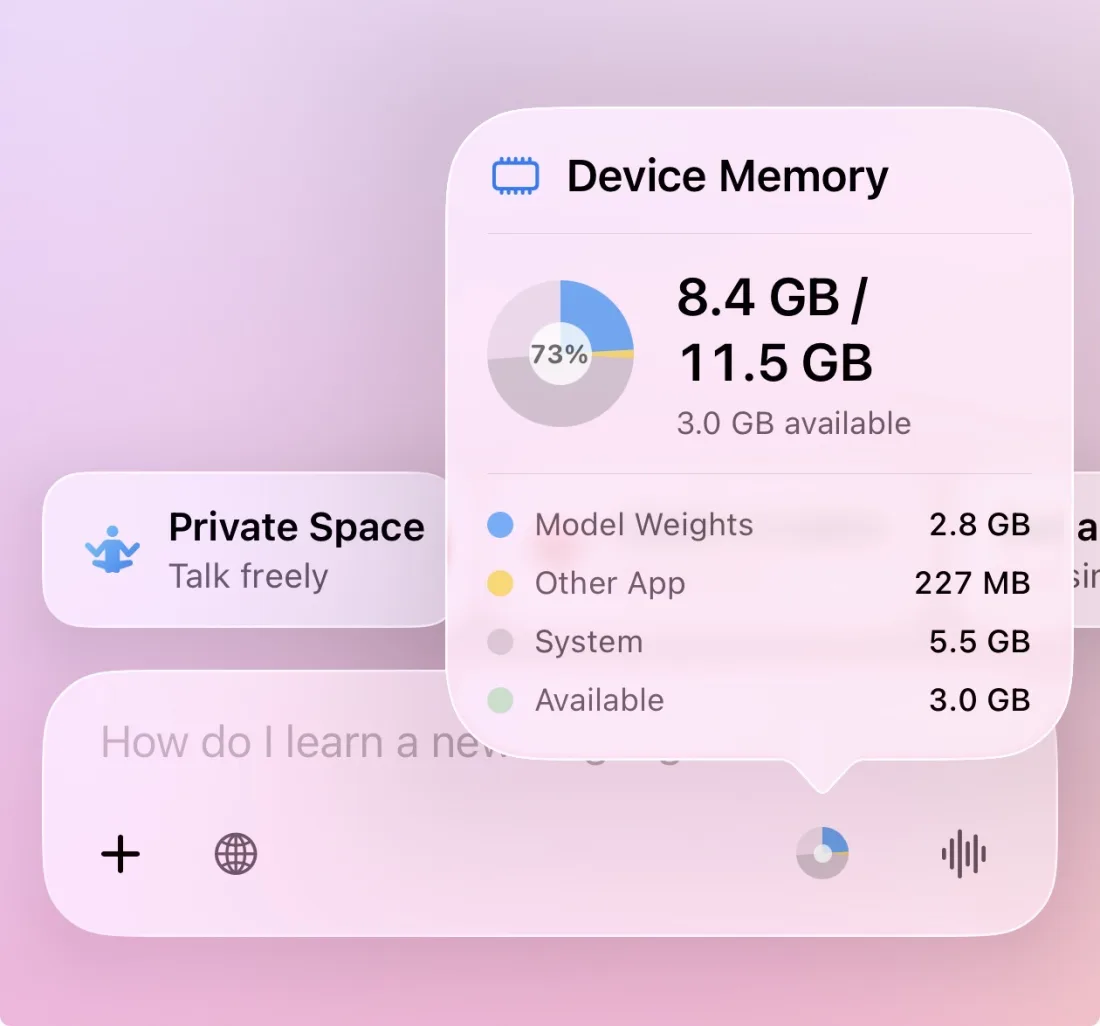
Device Memory Gauge
New memory breakdown shows model weights, KV cache, and system usage at a glance, with localized labels.
Date & Time Awareness
Models now know today's date and time, for more accurate, context-aware responses.
Apple Intelligence on LAN Server
Expose Apple's on-device foundation model as an endpoint on the LAN Inference Server, alongside your MLX models.
Stability & Performance
- Improved stability, much less likely to crash during long conversations or when using multiple features together (web search, images, health tools)
- Better memory management, the AI adapts to your device's available memory in real time, preventing out-of-memory crashes
- Cancel button works reliably, tapping stop during a response now works consistently
- Importing files no longer freezes the app, documents load smoothly in the background
- Faster generation stays stable, speculative decoding (2× speed mode) no longer crashes on longer conversations
- Startup crash prevention, in the rare case of a corrupted database, the app recovers automatically instead of getting stuck in a crash loop
Bug Fixes
- Fixed input field being locked when only Apple Intelligence was loaded with no MLX model present
- Fixed stuck streaming indicator after a crash, and prevented repeated crash loops on relaunch
- Reduced prefill step size to 512 to prevent out-of-memory crashes during prompt prefill with Gemma 4 MoE models
April 2026
Download Server Mirror
- New setting to choose download server: Auto, Global, or China Mirror (hf-mirror.com)
- Auto-detects your region for the fastest downloads
April 2026
LAN Inference Server
Turn your iPhone/iPad into an AI server. Load any model in Solair, flip the switch, and every device on your Wi-Fi can use it, just like OpenAI's API, but running entirely on your device.
See full details
How it works
- Enable the server in Settings > LAN Inference Server
- Any app that supports OpenAI or Ollama APIs can connect (Cursor, VS Code, Open WebUI, Python scripts, and more)
- Streaming responses, just like a cloud API
Compatible with
- OpenAI API, /v1/chat/completions, /v1/models
- Ollama API, /api/chat, /api/tags
Security
- Optional API key, generate a random key with one tap, or run without authentication on trusted networks
- Rate limiting, automatic protection against request flooding
- Connection limits, max 20 simultaneous connections
- DNS rebinding protection, blocks cross-origin attacks from malicious websites
- Credentials stored in Keychain, never in plain text
Setup guide built in
Includes connection instructions, code examples for Python and curl, and app-specific tips for Cursor, Open WebUI, and VS Code.
Good to know
- Server pauses when Solair goes to the background, keep the app open while serving
- Bonjour auto-discovery lets compatible apps find your server automatically
- Works over Tailscale for remote access
Add Models from Files App
You can now add MLX models directly through the iOS Files app. Place a model folder into the Solair models directory, restart the app, and it appears automatically in Your Models. Supports both author--model-name and author/model-name folder formats.
April 2026
Smarter Model Selection for Your Device
Solair now automatically picks the best AI smart models based on your iPhone's memory:
- 12GB devices (iPhone 17 Pro, iPhone Air): Qwen3 4B + Qwen3 VL 4B for maximum quality
- 8GB devices (iPhone 17, iPhone 16, iPhone 15 Pro): Qwen3.5 2B + Gemma 3 4B for balanced performance
- 6GB devices (iPhone 15, iPhone 14, iPhone 13 Pro): Qwen3.5 2B + SmolVLM2 for reliable operation
New Input Bar Design
- Beautiful aurora glow effect around the input field
- Animated suggestions cycle through helpful prompts
Improvements
- Sidebar opens more easily with lighter swipe
- Better download management with queued models
- Improved local model sharing, better reliability and transfer speed
- Camera improvements
- Fixed memory leaks with remote server connections
- Better Apple Watch voice playback
- Improved translations across supported languages
April 2026
Apple Watch App
Ask Solair from your wrist. Tap the mic, speak your question, and hear the answer. When Solair is running on your iPhone, queries are processed by your loaded local model. If the app is closed or your phone is locked, it falls back to Apple Intelligence seamlessly.
Local Model Sharing
Transfer AI models between your devices over Wi-Fi or Bluetooth, no internet needed. Great for setting up a new device without re-downloading gigabytes of models.
iCloud Backup Control
Option to exclude AI models from iCloud backup to save storage space.
Code Block Improvements
- Auto-scroll while AI generates code
- Line numbers for easier reference
- Syntax highlighting in edit mode
Accessibility
Improved VoiceOver accessibility for chat messages and settings.
April 2026
Improvements & Fixes
- Health Tools now work better across all AI models, including Chinese/Japanese/Korean
- Unified Smart+Vision, use one model (like Gemma 4) for both, no reloading
- Fixed tool recognition for Qwen3 and other models
April 2026
Bug Fix
- Improved stability when using web search with vision models (Gemma 4)
April 2026
Gemma 4 Support
Added new Gemma 4 family models (vision-language model) with full image understanding and tool calling.
Voice Mode Improvements
- Improved multilingual TTS pronunciation (French, Portuguese, Chinese, Italian, Spanish, Japanese)
- Added espeak-ng G2P for better pronunciation across languages
- Per-language voice preferences now saved
- Better CJK (Chinese/Japanese/Korean) sentence detection
Code Features
- New code preview with live rendering for HTML, JavaScript, p5.js, Chart.js, Three.js, D3.js, Mermaid diagrams, SVG, CSS, and Canvas
- "Ask AI to Fix" button for code errors
- Syntax highlighting in code blocks
- Save and persist edited code
New Models
- Added Qwen2.5-Coder models (1.5B, 3B, 7B)
- Added LFM2.5 350M model, a tiny, reliable data extraction and tool use model
- Model family logos in the All Models list
Other Improvements
- Faster model downloads with accurate progress tracking
- KV Cache Quantization, new setting to reduce memory usage by up to 75% during long conversations, letting you chat longer before running out of memory
- Enhanced tool calling for Health Intelligence
- More improvements under the hood
April 2026
10 Languages Supported
Solair is now available in Spanish, Chinese (Simplified & Traditional), Japanese, French, German, Korean, Portuguese (Brazil), and Italian on top of English.
Wikipedia in Web Search
Web search now includes Wikipedia as a knowledge source as an option with Grokipedia.
March 2026
Web Search Improvements
Complete overhaul of web search. The app now intelligently rewrites your questions into better search queries, handles complex multi-part questions by searching multiple times in parallel, and shows you exactly which sources were used in a new collapsible card.
35% Faster Text Generation
Under-the-hood performance improvements for Qwen 3.5 models. The MLX engine now processes tokens more efficiently on Apple Silicon.
Thinking Mode Toggle
New thinking mode button lets you enable deep reasoning for models that support it, like Qwen 3.5. Only in manual mode.
Qwen 3.5 & Nemotron Models
Qwen 3.5 is back in Auto Mode with proper thinking controls. New Nemotron model support added for even more choices.
Better Tool Calling
Fixed issues with AI calling multiple tools at once and improved handling of complex tool parameters. Health queries and other tool-based features now work more reliably.
Smarter Memory Extraction
Choose between Smart (AI-powered) or Fast (instant) methods for remembering facts about you. Smart mode understands context better, while Fast mode offers instant results.
Advanced Generation Settings
Fine-tune responses with new parameters: Top-K, Min-P, Presence Penalty, and Frequency Penalty. Try the Qwen 3.5 preset for optimal settings.
Bug Fixes
- Fixed Voice Mode over Bluetooth connections
- Fixed Shortcuts integration issues
March 2026
Personas
Chat with AI personalities tailored to your mood. Choose from built-in personas or create your own.
- Friends, Sam and Julia offer casual, supportive conversation like texting a real friend
- Historical Figures, Pick the brain of Einstein, Tesla, Da Vinci, Socrates, or Benjamin Franklin. Each speaks authentically from their era with unique insights
- Create Custom Personas, Create your own characters with custom names, personalities, and conversation styles. Built-in with a powerful AI creation tool
- Features iMessage-style chat bubbles, unique voice for each persona, and a beautiful golden selector in the sidebar
New Models
- Added Qwen 3.5 models (0.8B, 2B, 4B, 9B), latest efficient LLMs
Siri, Shortcuts & Widgets
- Ask Solair AI questions directly from Siri: "Hey Siri, ask Solair AI..."
- 15+ Shortcuts actions: Ask questions, translate, summarize, explain code, proofread, generate ideas, and more
- Works seamlessly with iOS Shortcuts app for custom automations
- New Siri & Shortcuts section in Settings
Voice Mode Improvements
- Faster AI response timing, reduced silence detection from 2.7s to 1.2s
- Thinking blocks now stripped from spoken responses
- Now 15 voices available (requires redownloading Kokoro)
Remote Server
- Added support for public HTTPS servers (OpenWebUI, etc.)
Speculative Decoding
Uses the fast model to speed up the smart model. Requires 2 models from the same family (e.g. Llama 3.2 1B and 3B).
Other Improvements
- Newly designed settings menu
- File size limit increased to 20 MB (from 5 MB)
- XLSX files now supported
- Better memory management for 8GB devices
- New option to enable web search by default
- Image results from web search
- Onboarding now lets you choose models or use defaults
- New Conversation Gesture, swipe left anywhere on the chat screen to instantly create a new conversation
Bug Fixes
- Fixed health tools appearing when HealthKit isn't set up
February 2026
Health Intelligence
A groundbreaking feature: ask about your steps, sleep, heart rate, workouts, and more, all processed on-device.
- 9 data types: Exercise Time, Standing Hours, VO2 Max, Heart Rate Recovery, Walking Steadiness, Blood Pressure, and Menstrual Cycle with calendar visualization
- Weekly reports and trend analysis factoring in all available metrics
- All data stays on your device, never uploaded
Note: Health Intelligence is for informational purposes only and not medical advice.
Private Space
New prompt stack for personal conversations: emotional support, anxiety help, private journaling, relationship advice, and a safe space to vent. Everything stays completely on-device.
Remote Server
For power users: connect to your own LLM servers via Tailscale VPN. Supports Ollama, vLLM, and OpenAI-compatible APIs with auto-discovery and secure credential storage.
Expanded File Import
- PDF, TXT, CSV, JSON, Markdown, HTML, and 25+ programming languages including Swift, Python, JavaScript, and more
Mac & iPad Improvements
- Native Mac Catalyst support for better performance
- Optimized memory management on all platforms
- Improved layout and UI
February 2026
Initial Release
The first versions of Solair AI, a private AI assistant that runs entirely on your iPhone and iPad. No servers, no accounts, no data collection. Chat with local LLMs, attach images and files, talk with Voice Mode, and get intelligent responses without ever going online. Super fast, built to be the best and most polished local AI app.